At approximately 3:00am ET on October, 20, 2025, Amazon Web Services (AWS) experienced a significant outage and continues to escalate throughout the day, eventually recovering around 6:30pm
AWS serves as the provider of many internet and service-related offerings globally. Thousands of large (and small) organizations rely upon AWS to keep them operating 24/7/365. The data center impacted was their US-EAST-1 location which is regionally in northern Virginia. This data center serves as one of the distribution management locations that controls the location and distribution of AWS services globally. This makes the location particularly critical to Amazon’s entire infrastructure.
AWS reported $108 billion in revenue for 2024.
How could one data center result in a near global Internet outage?
With outages of this level, there are days (if not weeks) of recovery. And more questions than answers. Let’s dive in.
What Happened?
Shortly after 3:00am ET, one of AWS’s regional data centers suffered an outage. The outage was central to Amazon’s DynamoDB platform. DynamoDB is one of AWS’s modern database platforms used by thousands of organizations to collect, manage and store data. The specific instance of DynamoDB impacted managed Amazon’s DNS entries. DNS is the service that translates domain names (www.cybersecurity.tax) into the machine-focused IP addresses (a collect of numbers unique and specific to each machine on the Internet. This creates a digital address book of the Internet. And Amazon’s address book is one of the largest and most heavily used systems globally. It essentially is the GPS for almost half of the Internet.
Two and a half hours later, the problem was fully diagnosed and resolved. However, we were far from out of the woods.
Due to the prolonged outage of the DNS service, it created a backlog of requests which rippled through Amazon’s EC2 services. EC2 is Amazon’s Compute Services, the systems which provide virtual machines to thousands of companies and users globally. New instances and virtual machines were not able to launch and existing systems faced throttling issues. It was determined that the root cause of this issue centered around a health monitor for a load balancer. A load balancer is designed to ensure that requests and services are spread out around multiple systems, reducing the strain on a single source. Ideally, it’s the system that manages a huge traffic pattern, ensuring that enough traffic is evenly spread around to avoid a jam.
Over the next several hours, services continued to waiver up and down. However, ultimately, by 6:30pm, services were stabilized globally and by 7:00pm, Amazon closed the ticket marking it as Resolved.
You can read more about the full technical details here on their Health page.
Who Was Impacted?
Those impacted could ultimately be labelled as almost anyone with Internet access. But in seriousness…
Outages included Snapchat, Ring, Venmo, Signal, Fortnite, Lyft, Roblox, Amazon, Perplexity, Canva, Duolingo, Netflix,, Amazon, Reddit, Apple TV/Music, McDonalds, OpenAI, Worldle, Google Maps, YouTube, reCAPTCHA, AT&T, Discord, DoorDash, Etsy, Cloudflare, Mailchimp, Lyft, Airbnb, Disney+, and thousands more.
From Financial Services, known outages included TaxDome, Coinbase, and Robinhood.
AWS is also the provider of GovCloud services focused on provider cloud-based solutions to government entities. The UK has acknowledged they experiences service disruption. Minimal disruptions have been acknowledged from US-based agencies.
How Is Recovery?
Amazon has stated that all outstanding issues have been resolved; however there are still significant backlogs that are being processed. They believe the backlog should be caught up by midnight ET.
With an outage of this scale, there are bound to be small, ripple effects for several days across multiple systems and providers.
How to Handle a Future Outage?
When working with cloud services, it can be expected that future outages will occur. Rather than hoping for perfection, it is better to plan for what might come.
A first step for future planning is to ensure you understand what technology and platforms your software and vendors use. Ask them. Probe if you have to.
Here are key actions to take during an outage:
It is important to follow the directions of the impacted vendor to ensure you to no place your data at greater risk.
Do not continue to use (or attempt to use) impacted applications.
Minimize overall Internet usage. Weaknesses abound in vulnerable systems. The movies or music can wait.
Give the impacted system time to properly recover. Many systems immediately fail upon recovery due to increased traffic of users all trying to simultaneously log in.
Take a break. It’s better to not push a system. And don’t push yourself.
More importantly, do not panic. Panicking will not improve the situation. Stay calm. Stay cool. You will make it through this. Have some tea. :)
To Cloud or Not To Cloud?
This is one of the biggest questions out there. Is it best to use cloud services or not? Before we dig into that discussion, let’s look at the options available:
Cloud Hosting: a model where an organization’s applications, storage, and infrastructure are hosted by a third-party provider (such as AWS, Microsoft Azure, Google, etc) and accessed via the Internet. Resources are typically scalable on demand, and the third-party handles maintenance, updates, and security at the infrastructure level.
On-Premise (On-Prem): Managing servers, storage, and software within an organization’s physical location. The business owns and maintains the hardware and is responsible for system administration, updates, and data security.
Hosted Solutions: A hybrid model where a third party hosts software or infrastructure for an organization, often in a private data center. Unlike fully public cloud solutions, hosted environments can offer dedicated hardware and more customized configurations.
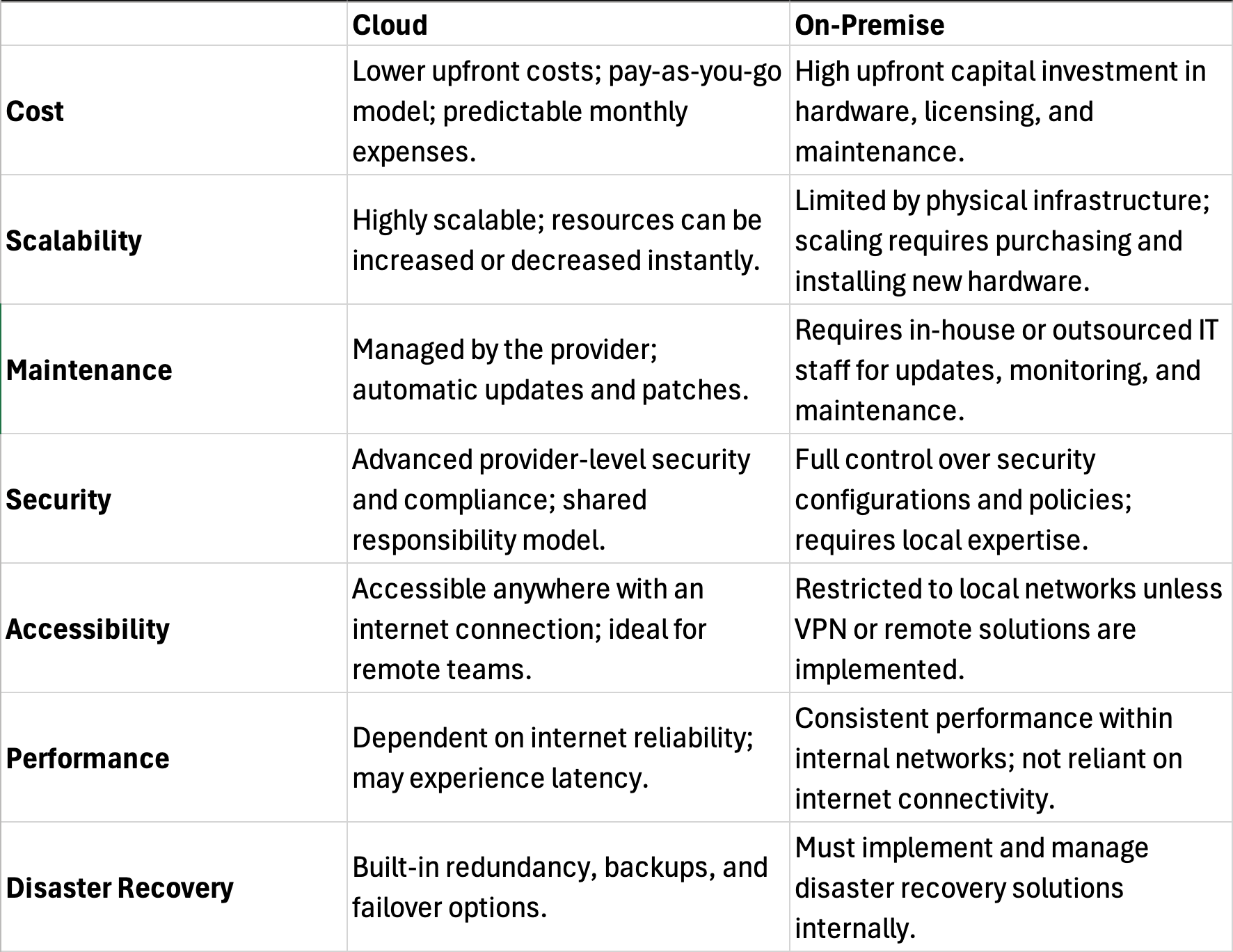
The debate of cloud versus on-premise solutions has waged for years and will continue to for years to come. The below chart is a high-level analysis of the comparable key points.
As for my firm, we are on-premise with 80% of our solutions. I prefer this from a security and data access perspective. I also love the fact that, on days like today, I don’t have to worry about what is happening outside of our walls. Even in situations where we have utility outages, we are able to continue running.
This is a really complicated and challenging topic. If you have any questions or would like assistance, we are available to help! Contact us at www.cybersecurity.tax.
Financial Guardians is the premiere provider of cybersecurity and technology assistance, education, and support to the tax preparation, accounting, and financial services industry. With a network of several thousand firms and professionals, we are the largest source of unbiased security information in the industry. More information can be located at www.cybersecurity.tax.
Financial Guardians has partnered with NAEA to provide access to our monthly Guardian Tier membership at a 30% discount.
Financial Guardians is a proud member of InCite, the recently launched online community exclusively for tax professionals, bookkeepers, and accountants. InCite members receive a 30% discount.
Financial Guardians has partnered with the California Society of Tax Consultants to provide a 30% access discount as well as many other offers. More info can be found at www.cstcsociety.org